Scale Yourself Report / Owner application / 2026
How I scaled
myself with AI
This is how I've been working for the past year. The clearest example is one side project: I shipped LoveCompass — a wellness app for couples, live on web, iOS and Android — as 1,001 merged PRs in three months, with strategic human gates on each feature development cycle / decision.
Primary focus: LoveCompass · Mar 09 – Jun 06, 2026Summary
The volume came from building the right scaffolding and then getting out of its way. AI agents handle code review across four dimensions, a deterministic CI pipeline gates every merge, and a dashboard keeps everything visible. I step in for feature decisions and direction — the rest runs. Along the way I picked up patterns I find genuinely interesting: Deterministic Simulation Testing, saga orchestration, intuition engineering, RAG-based self-improvement.
- 1,001 merged PRs in 3 months across web, iOS and Android — peak of 67 in a single day (Mar 17), sustained 11/day.
- AI reviews, I decide — security, architecture, performance and test-quality agents flag issues on every PR; strategic human gates on each feature cycle.
- Deterministic quality gates — 100% of merges pass human-defined checks on a self-hosted + Kubernetes (ARC) CI cluster.
- Observable by design — IntuitionOps dashboard + custom Langfuse tracing (built around Claude subscriptions, not the pay-as-you-go API) surface cost, latency and stuck agents in real time.
- Compounding leverage — every merged PR triggers automated learning extraction; a human curates the entries; approved learnings feed back into future agent runs via LanceDB RAG.
Merge velocity
The required chart, and the shape of the work: a heavy build-out in March, refinement in April, then sustained shipping through May.
The product: LoveCompass
A full-stack wellness app for couples, shipped across three platforms using AI-assisted development pipelines — automated multi-dimensional review backed by deterministic testing.
| Property | Detail |
|---|---|
| Platforms | Web · iOS · Android |
| Live | couplesapp.nextasy.co |
| Window | Mar 09 – Jun 06, 2026 |
| Throughput | 1,001 PRs · 11/day avg · 67 peak |
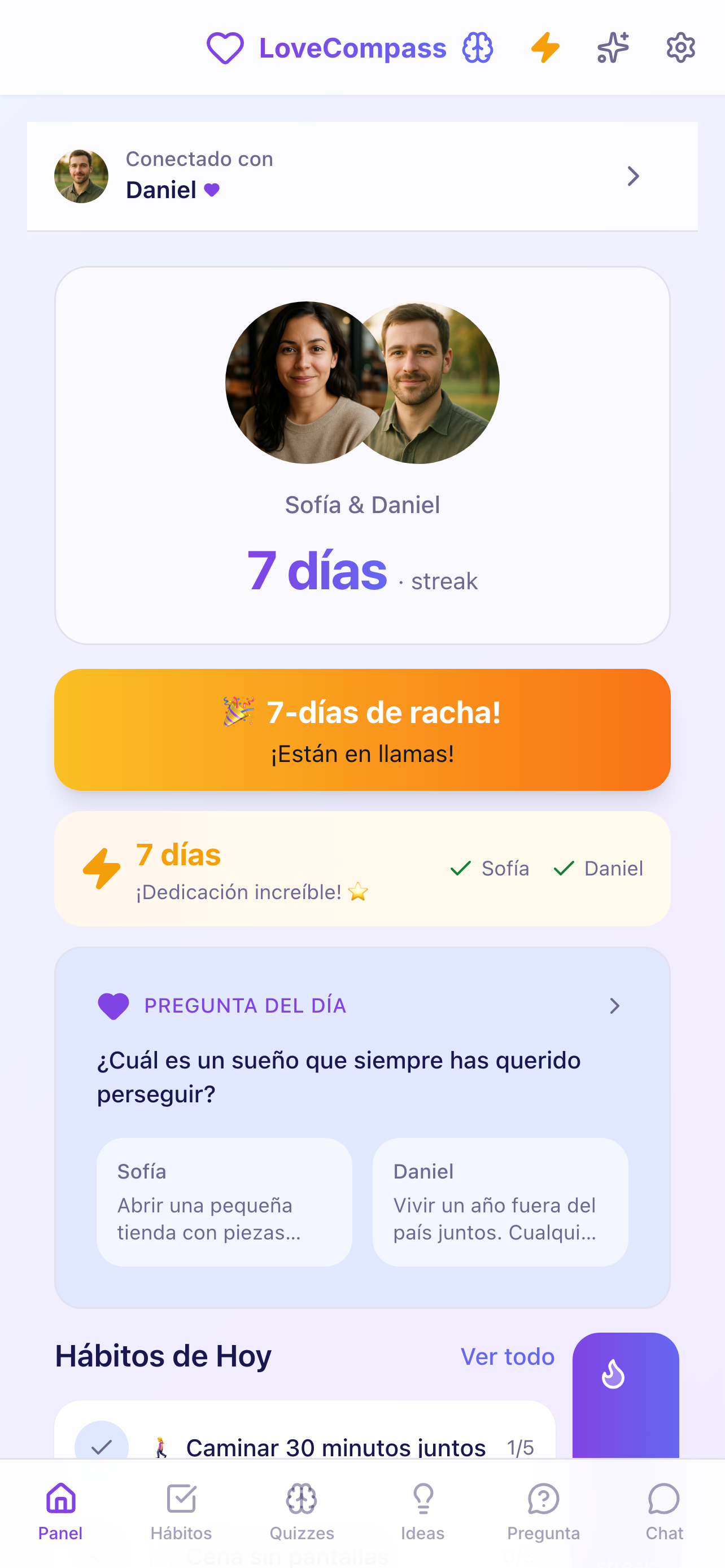
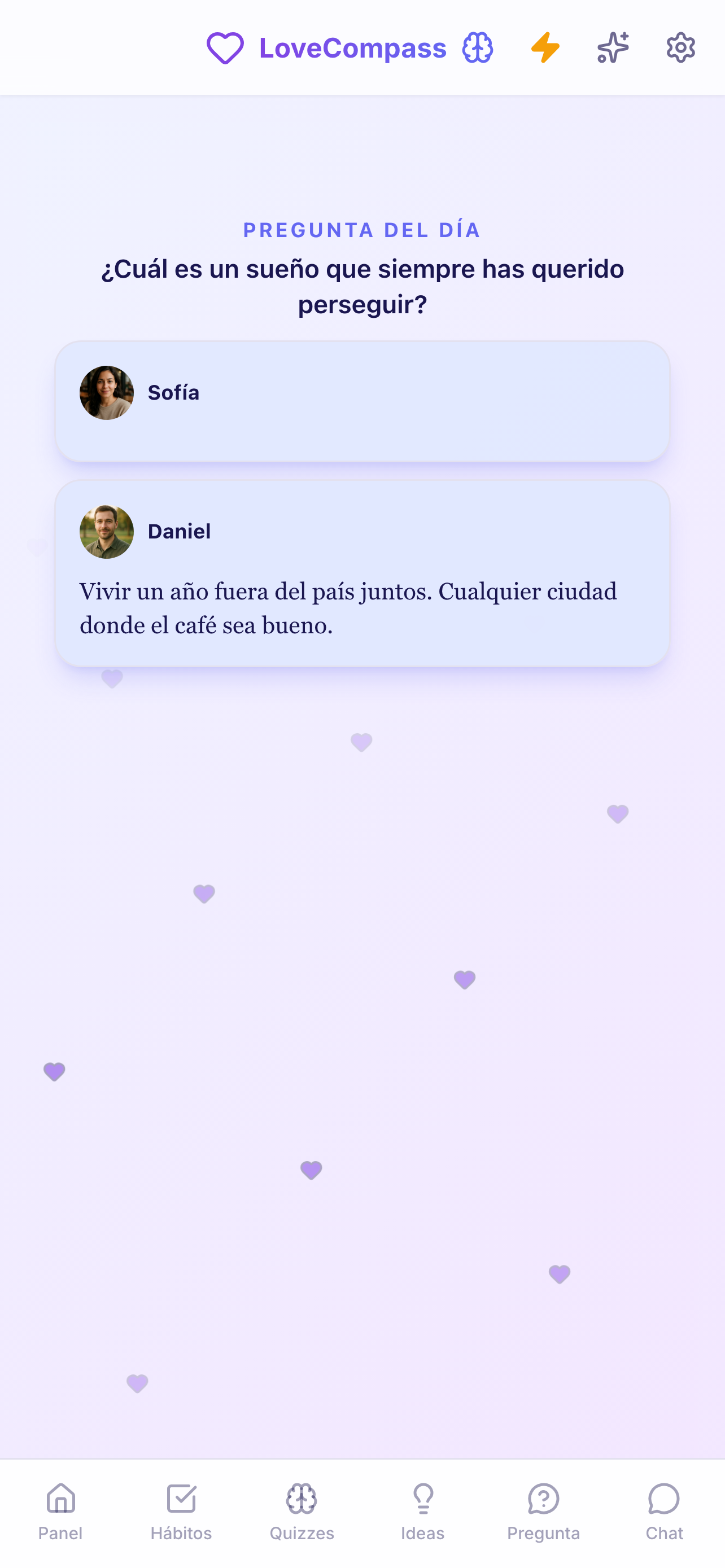
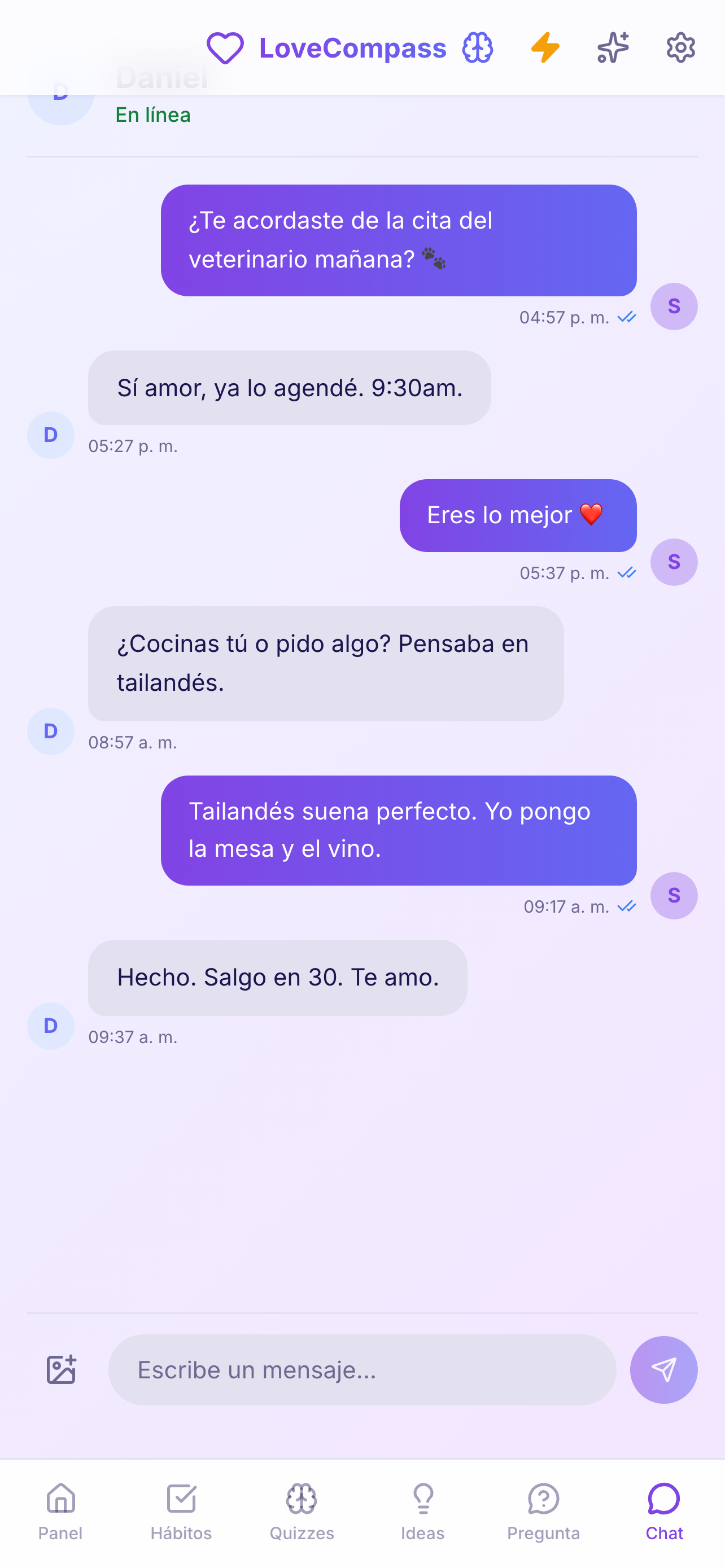
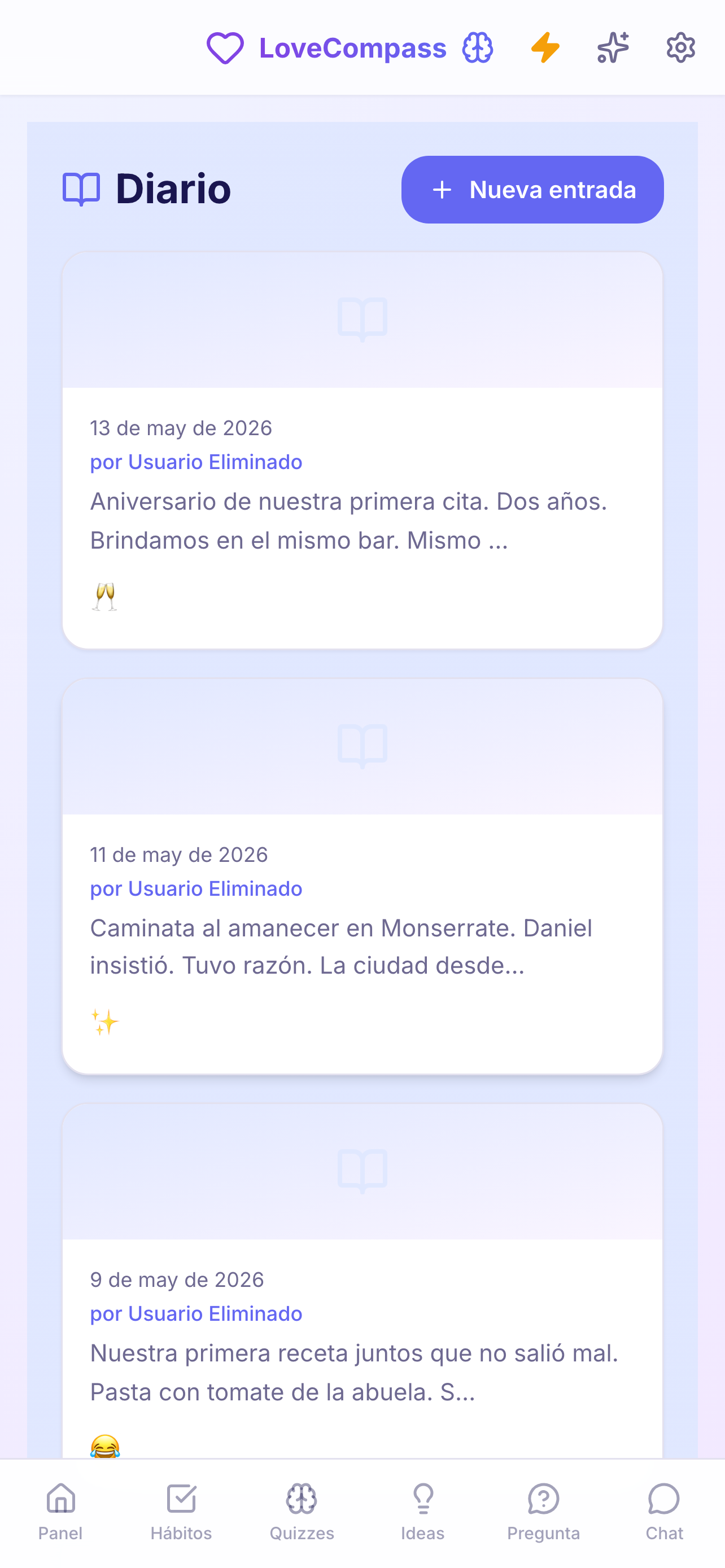
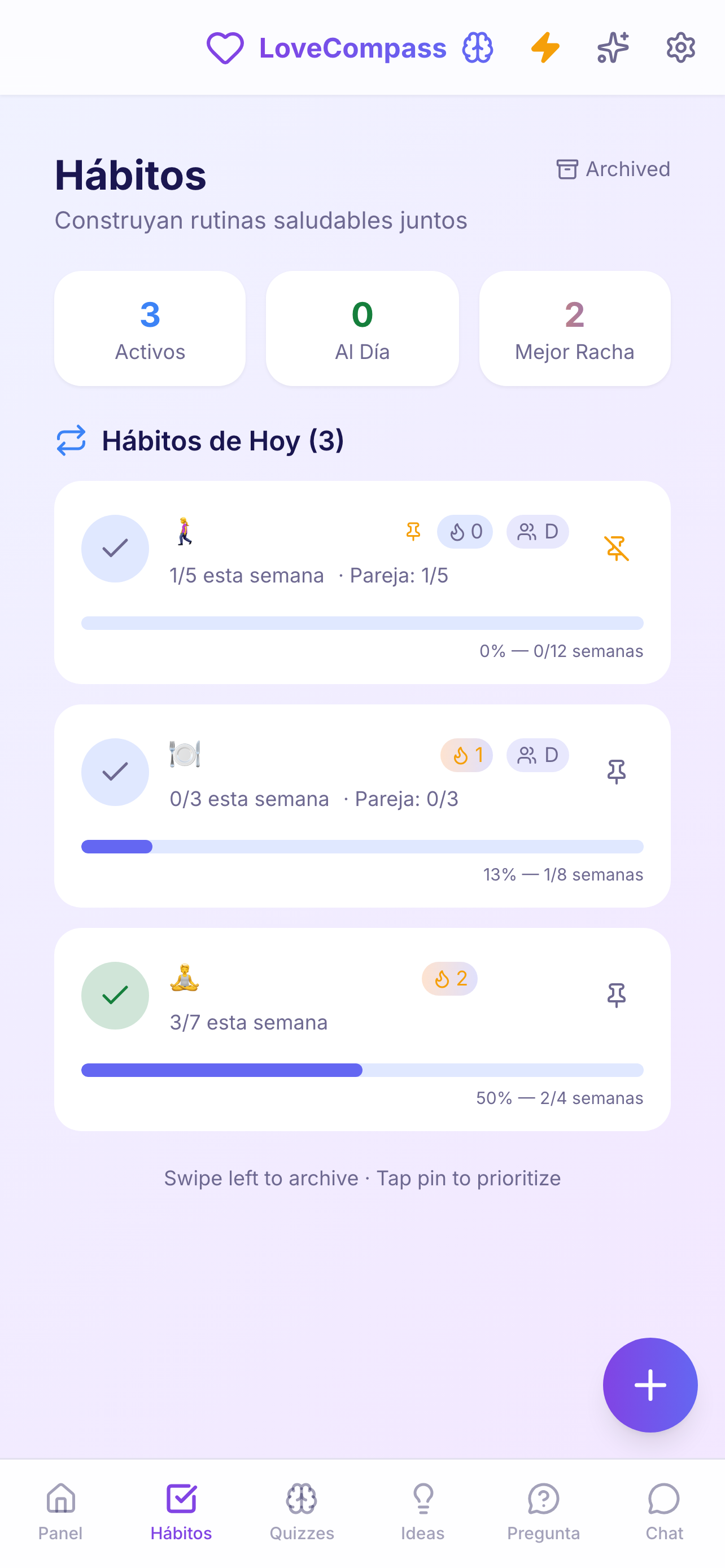

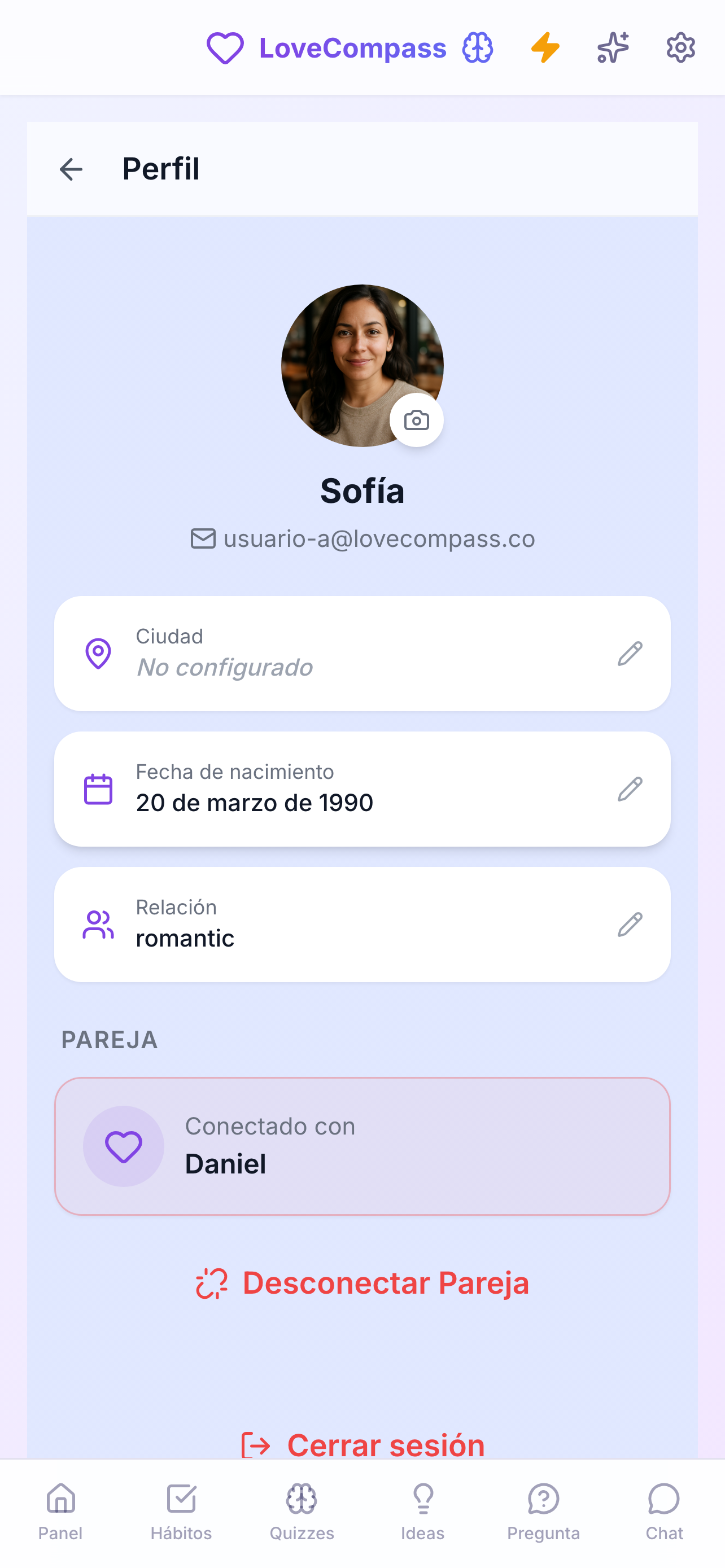
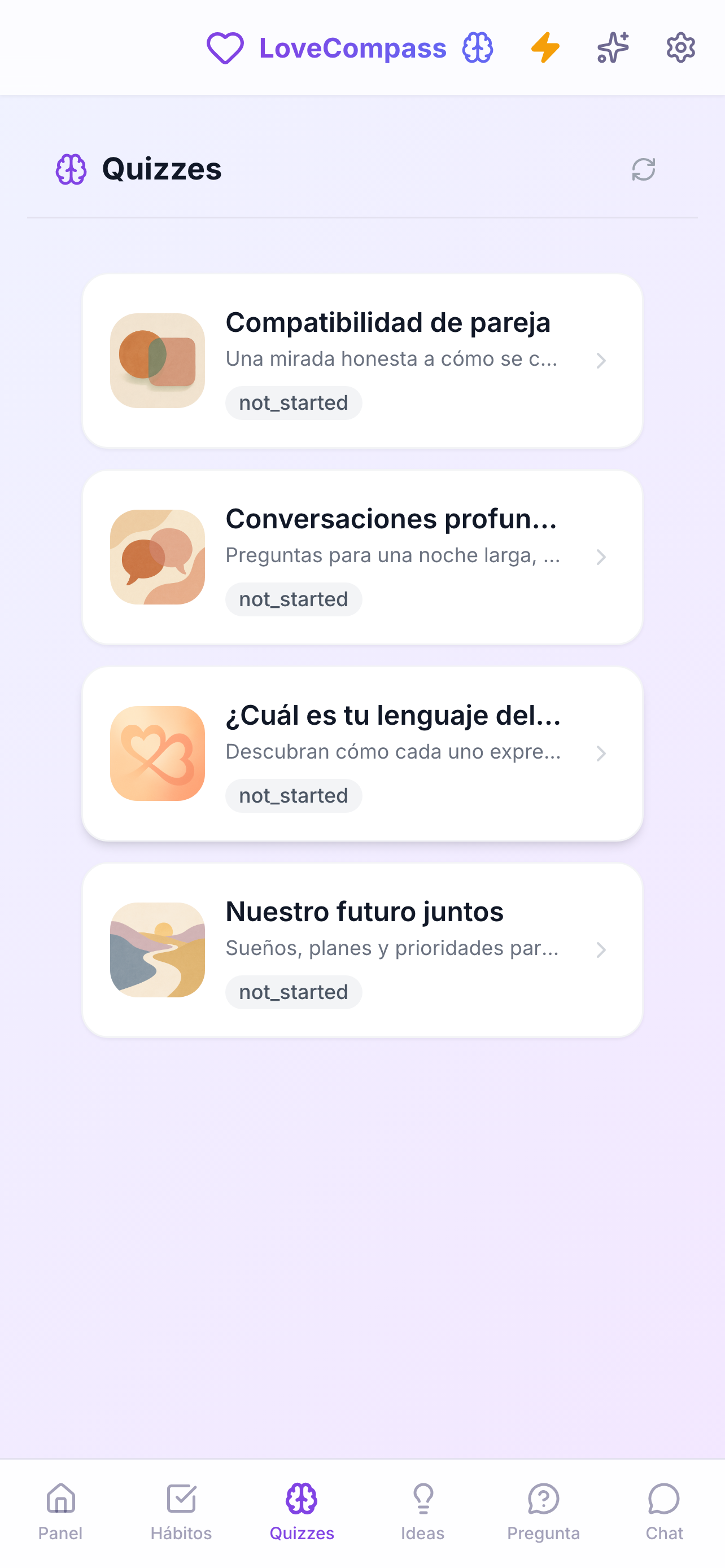
scroll → · click to expand
How it shipped: the pipeline
Here's what's actually running under the hood. These aren't magic — each one is a thing I had to build, debug, and tune before it was useful.
Agent-assisted code review
At this PR volume, manual review on every dimension isn't realistic. Four agents run in parallel, each focused on one area, and iterate with the dev up to three times per PR until their gate passes:
- Security — OWASP Top 10, credential leaks, dependency CVEs
- Architecture — ADR alignment, design patterns, boundaries
- Performance — latency, memory, throughput, algorithmic cost
- Test quality — assertion depth, E2E coverage, flakiness
Deterministic testing infrastructure
Model behaviour is non-deterministic — you can't rely on it for correctness gates. So I kept those separate: a three-phase pipeline that runs the same way every time, regardless of what the agents do:
- Husky (pre-commit) — local lint, format, fast rules before push.
- Self-hosted runners — full unit / integration / E2E suite across 3 platforms; blocks merge until green.
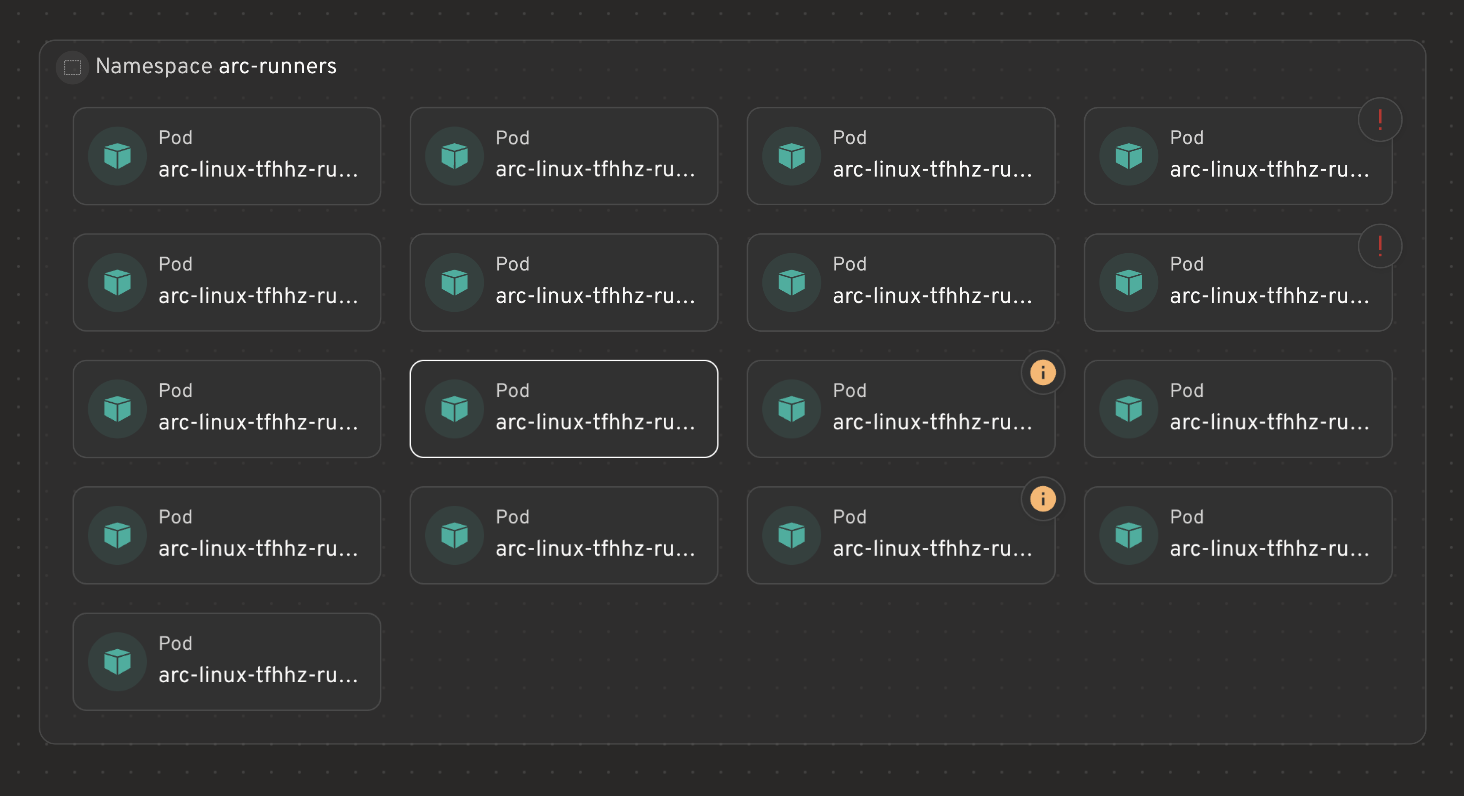
- ARC cluster (Kubernetes) — ephemeral runners auto-scale with PR volume: E2E, architecture validation, security scanning, performance baselines. Peak: 20+ concurrent jobs.
Result: 100% deterministic validation on all 1,001 merges. Zero AI decision-making on merge eligibility — only human-defined gates. Snapshot (Jun 06): K8s cluster running 20 pods, ~1.1 merges/hour at peak.
Live ARC cluster — Jun 06, 2026 · click to expand
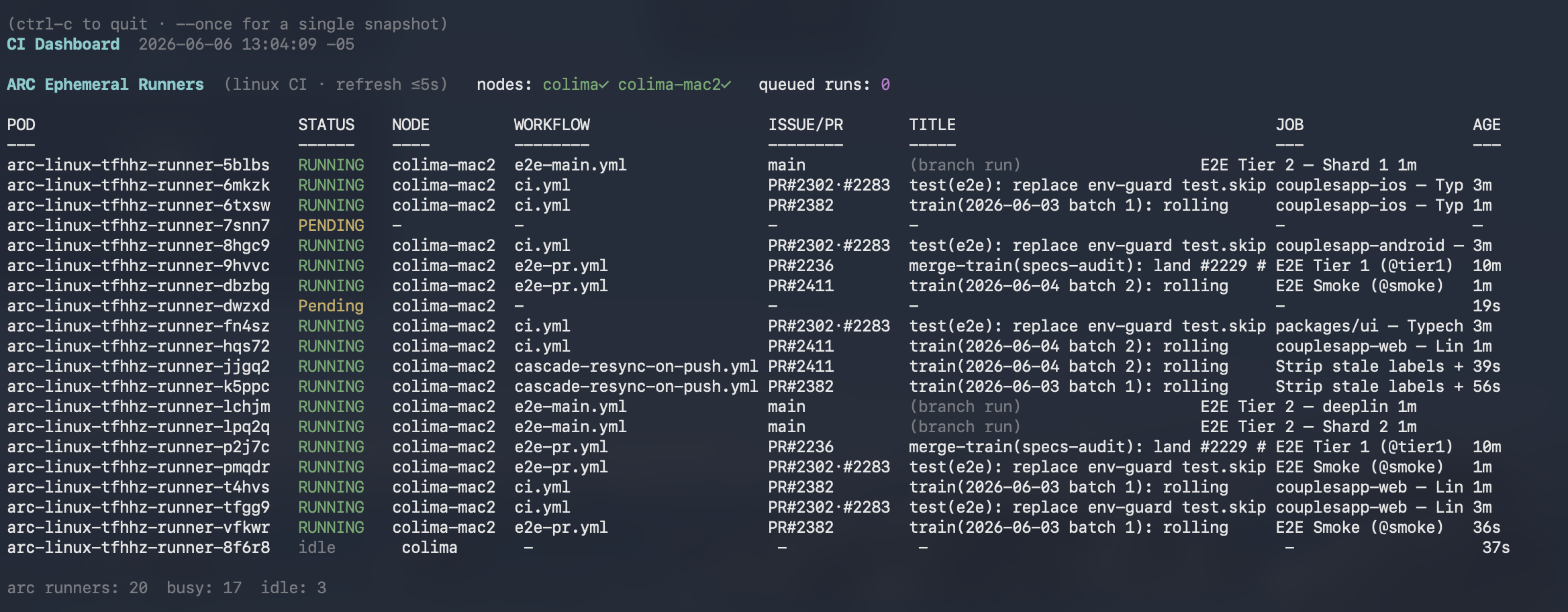
IntuitionOps — real-time pipeline dashboard
The thing I didn't anticipate: agents running 24/7 are hard to watch. Non-deterministic behaviour, surprise token costs, agents deadlocking — you only find out from the bill or a stuck queue. I built IntuitionOps to make the pipeline readable at a glance, borrowing a few old distributed-systems ideas:
- Deterministic replay (FoundationDB) — scrub real pipeline history minute-by-minute
- Saga orchestration (AWS pattern) — multi-step agent coordination with failure handling
- Intuition engineering (Netflix Flux) — visual flow you read at a glance, not just numbers
- Multi-agent tracking (ClawLibrary) — each agent's context usage and state
Result: token cost is a first-class signal, stuck agents light up instantly, and infinite agent loops show as cost climbing while merges stay flat. Read the full write-up →
IntuitionOps dashboard · click to expand
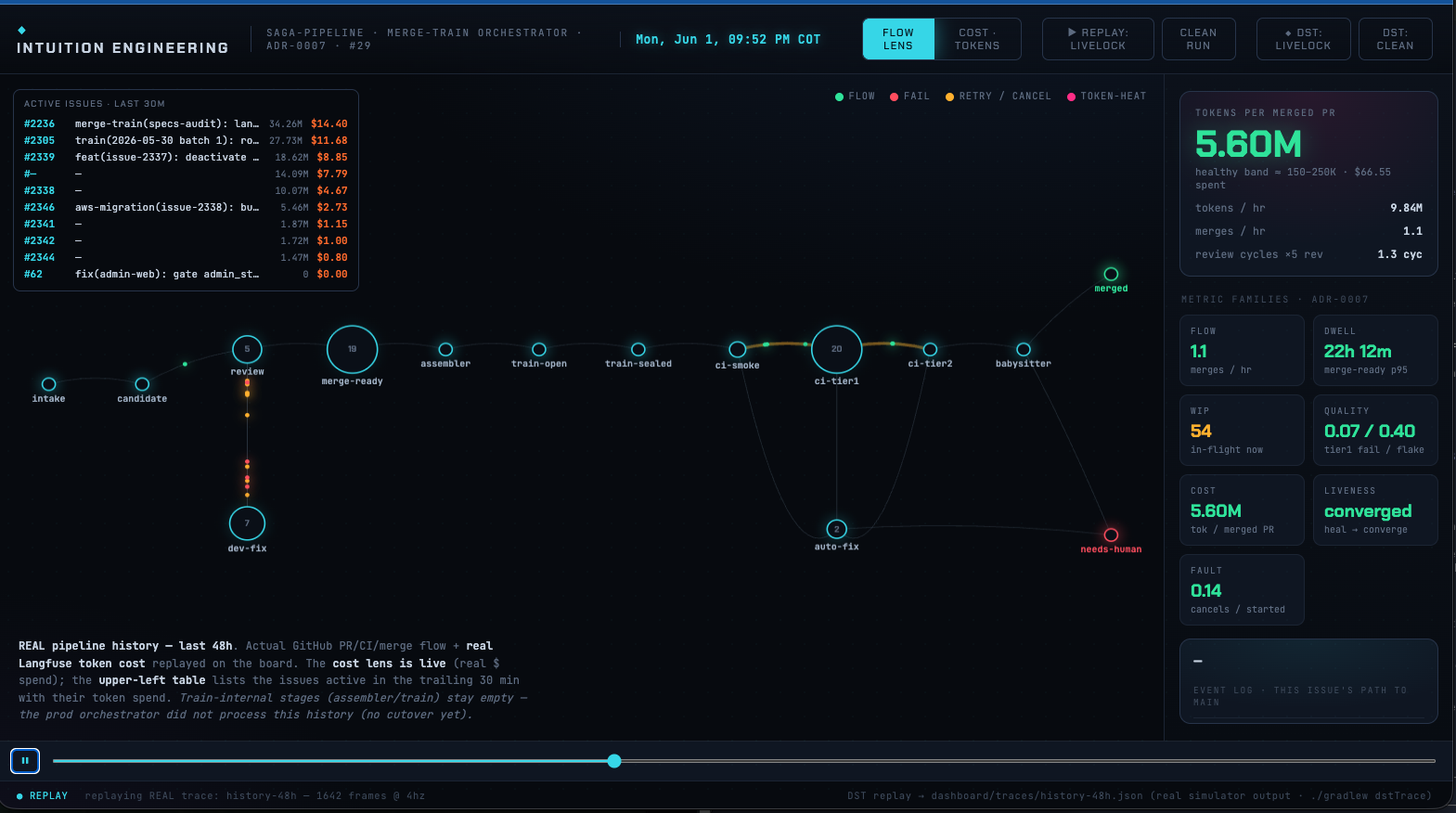
Per-issue traceability in Langfuse — without the API
The pipeline runs on Claude subscriptions, not pay-as-you-go API tokens. That means the standard Langfuse SDK instrumentation doesn't apply — there's no API call to intercept and no token counter to hook into. To get per-issue visibility anyway, I built a custom tracing layer that publishes traces to Langfuse independently of the model calls:
- Manual trace publishing — each pipeline run explicitly posts a trace to Langfuse keyed to the GitHub issue number, not inferred from an API response
- Issue-level aggregation — latency and outcome grouped by issue, so I could see cost and duration per feature shipped
- Agent-level spans — each subagent (security, architecture, etc.) posts its own span, making slow or failing agents visible without SDK hooks
Self-learning pipeline — RAG over merged issues
Every merged PR is an opportunity to learn. After merge, an automated agent extracts learnings from the issue — gotchas, patterns, decisions — and proposes them as structured entries. A human reviews and approves what's genuinely worth keeping. Approved entries are embedded and stored in LanceDB, and every future agent run queries that store before acting:
- Trigger: automated extraction fires after each merge — no manual step to capture the lesson
- Human in the loop: a human reviews proposed entries before they land in the knowledge base — filters noise, keeps signal
- RAG retrieval: agents query LanceDB for semantically similar past entries before starting work on a new issue — context from real decisions, not generic prompts
- Compounding effect: the more PRs merge, the richer the context the next agent gets — the pipeline gets smarter with use
Leverage beyond the product
Published & integrated
Standing on proven shoulders instead of reinventing:
- token-optimization — published harness for LLM token-reduction testing
- pipeline-installer — published; install autonomous AI dev pipelines in 30 min
- mempalace — integrated for semantic memory; reported + fixed bugs
- rtk — CLI token-reduction proxy; validated 60–90% savings
- ClawLibrary — contributed to a shared AI-dev foundation
Workflows automated
- Autonomous PR review agents (4 dimensions)
- Multi-platform build pipeline (web · iOS · Android in sync)
- Session-based AI memory (semantic search + journal mining)
- Langfuse observability (cost & latency attribution)
- Deployment safety checks (env isolation, health verification)
Velocity breakdown
| Metric | Value |
|---|---|
| Total merged PRs | 1,001 |
| Average PRs / day | 11 |
| Peak day | 67 — Mar 17, 2026 |
| Top 3 days | 67 (Mar 17) · 54 (May 18) · 47 (Mar 26) |
| Full PR log | all 1,001 PRs — searchable → |
This is just how I work now. Build the scaffolding, set the gates, stay in the loop for the decisions that matter. The volume is a side effect of having good tooling — not the goal itself.
Appendix — Ask-Marcus chatbot
A separate side-project, included as a second data point. It isn't part of the LoveCompass story above — it's another example of the same AI-leverage instinct applied to a different problem: answering recurring questions about me, safely.
6-rail defense pipeline
Answer recurring questions about me automatically while resisting jailbreaks and off-topic abuse. Each request flows through six guard rails:
- Request validation
- Topic classification
- PII detection
- Jailbreak detection
- Llama Guard
- Claude brain (subscription auth)
Live at marcuss.pro · handles adversarial input · observable via Langfuse · single-command recovery.